April 22, 2026
Compound noun chaos: How AI deconstructs (and misinterprets) German words
German is one of the ten most-translated languages in the world, and it has a specific, well-documented failure mode in AI translation systems that most localization teams discover late – usually mid-review, usually on a deadline.
The failure is not random. It follows a predictable pattern tied to a single structural feature of the German language: compound nouns. And because it is predictable, it is preventable – once you understand what is actually happening inside the model when it encounters a 35-character technical term it has never seen before.
This article explains the mechanics of that failure, maps it to the document types where it causes the most damage, and outlines the workflow decisions that prevent it from reaching your published content.
Table of contents
Why German compound nouns are unlike anything in English
Three documented ways AI segmentation breaks down
A comparison: How different MT approaches handle the same compound
Where these failures cause the most damage
The glossary-first approach to preventing compound noun errors
How MachineTranslation.com's SMART system addresses compound noun risk
FAQs
Why German compound nouns are unlike anything in English
English builds complex concepts out of word phrases: "fuel injection pump," "data protection officer," "quality assurance measure." These are multi-token sequences that AI systems handle through standard phrase-level pattern matching; the models have seen these combinations thousands of times and translated them reliably.
German compresses those same concepts into single words: Kraftstoffeinspritzpumpe, Datenschutzbeauftragter, Qualitätssicherungsmaßnahme. No spaces. No hyphens. No visible boundary between the constituent parts. The language's compounding rules are theoretically unlimited – any two or more nouns can be joined to form a new word, and new compounds are coined continuously in technical, legal, and regulatory writing.
For a neural MT system, this creates a fundamental pre-translation problem. Before the model can assign meaning, it must perform segmentation: decide where one semantic unit ends and the next begins. For common compounds that appear frequently in training data, the model has learned this boundary implicitly. For rare, domain-specific, or newly coined compounds (the kind that appear constantly in engineering documentation, pharmaceutical labelling, and EU regulatory filings), the model is guessing.
What happens when it guesses wrong is predictable and specific.
Three documented ways AI segmentation breaks down
The wrong segmentation cut
The model cuts the compound at the wrong morphological boundary. Sicherheitsventildruckabfall (safety valve pressure drop) might be parsed as Sicherheitsventil (safety valve) + druckabfall (pressure drop), which is correct – or as Sicherheit (safety) + sventildruckabfall, which is not a word. The second outcome produces either a garbled output or a fallback to a generic approximation.
In technical documentation, this matters because the correct segmentation is rarely the only plausible one. Kraftstoffeinspritzpumpengehäuse (fuel injection pump housing) can be cut in at least three places with three different (and all superficially plausible) English translations. A model outputting "fuel injection pump casing" in one paragraph and "fuel injection pump housing" in the next has not made an error any reader would immediately flag. But a terminologist reviewing against a DIN standard will catch it, and in certified documentation, it is a conformance finding.
Literal back-translation from components
The model correctly identifies the component parts but translates each one without recognising that the combined whole is a fixed, domain-specific term with an established English equivalent.
Datenschutzbeauftragter is "Data Protection Officer", a precise legal role defined in Article 37 of the GDPR. The compound breaks into Datenschutz (data protection) and Beauftragter (officer, commissioner, appointee, representative). A model that processes these components independently can output "data privacy commissioner," "data protection appointee," or "data security representative" – all semantically coherent, none legally correct, and none matching the term your lawyers, regulators, and English-language compliance documentation use.
This failure mode is particularly acute for EU regulatory terminology, where compound nouns encode precise legal concepts that have official English translations. Variance from the official term is not a style issue; it is a compliance issue.
Non-translation: the German word survives untouched
For very long or highly domain-specific compounds that fall entirely outside the model's training distribution, some systems simply pass the German word through unchanged. An English-language technical manual that includes Verdichterverhältnisverstärkungsregler in the middle of a paragraph is unreadable to its intended audience. This outcome is the easiest to catch in review (it is visible immediately) but it still represents a workflow failure if it reaches the reviewer's desk rather than being prevented upstream.
A comparison: How different MT approaches handle the same compound
The following table illustrates how the same source compound can produce different outputs depending on the approach used, ranging from raw MT output to glossary-guided MT to human post-editing:
German compound | Raw MT output (example) | Glossary-guided MT | Human post-edit |
Datenschutzbeauftragter | "data privacy commissioner" | "Data Protection Officer" | "Data Protection Officer" |
Sicherheitsventil Druckabfall | "safety valve pressure decrease" | "safety valve pressure drop" | "safety valve pressure drop" |
Kraftstoffeinspritzpumpe Gehäuse | "fuel injection pump casing" | "fuel injection pump housing" | "fuel injection pump housing" |
Qualitätssicherungsmaßnahmen | "quality assurance actions" | "quality assurance measures" | "quality assurance measures" |
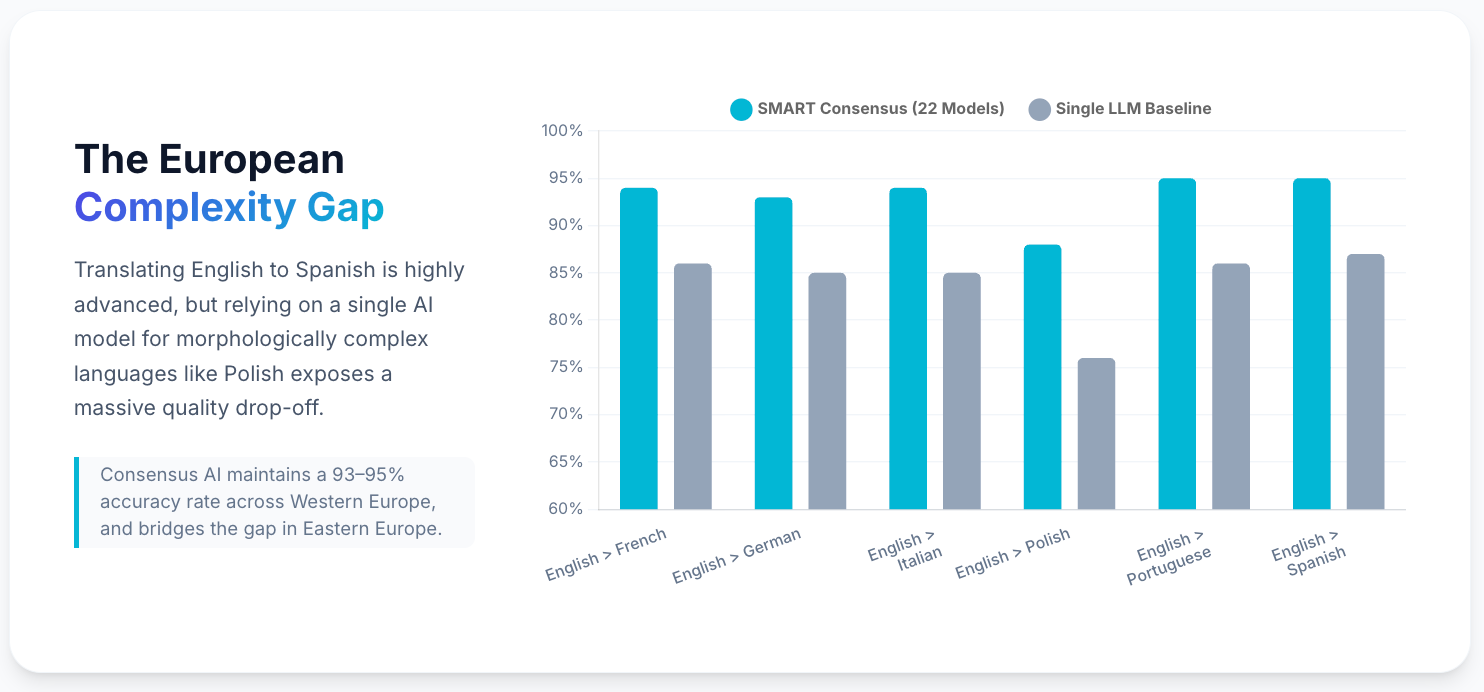
The pattern is consistent: where a glossary provides the correct target-language term before translation begins, the output matches the human post-edit. Where no glossary exists, the raw MT output is plausible but wrong – and wrong in the specific, consistent way that makes it hardest to catch without domain expertise.
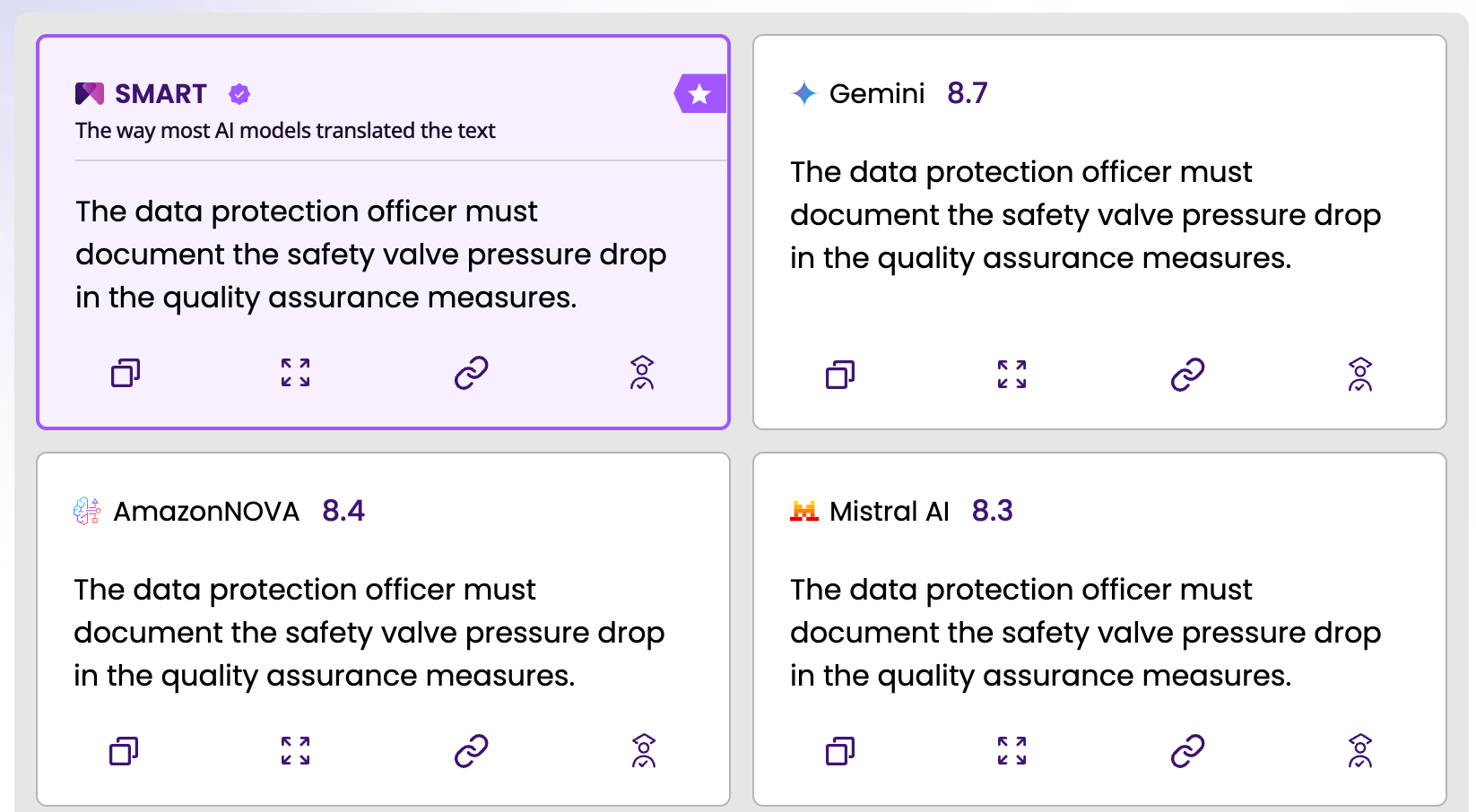
Where these failures cause the most damage
Not all German content carries the same risk profile for compound noun errors. The damage is proportional to three factors: how rare the compound is in the model's training data, how precisely the target-language term is defined in the relevant domain, and how consequential a variance from the correct term is for the document's purpose.
Regulated industries carry the highest risk - Medical device documentation (under EU MDR), pharmaceutical labelling, and aviation maintenance manuals all require consistent, certified terminology. A compound noun error in these documents does not merely reduce quality, it can trigger a conformance finding or require resubmission.
Legal and contractual documents are the second tier - EU GDPR compliance documentation, contract terms, and regulatory filings use compound nouns to encode specific legal concepts. Variance from the established English term (even when semantically close) can create ambiguity in the document's legal interpretation.
Technical documentation and product manuals represent the highest volume - Engineering documentation from German manufacturers contains a disproportionate density of domain-specific compounds. The error rate is high, the review burden is substantial, and the published content directly affects how customers use and maintain complex equipment.
General business correspondence, marketing content, and internal communications are lower risk. Compounds appear less frequently, are more likely to be common, and the consequences of imprecision are less severe.
The glossary-first approach to preventing compound noun errors
The most effective mitigation for compound noun errors is also the most straightforward: build a domain-specific termbase before translation begins, upload it to the MT system, and let the controlled vocabulary override the model's default segmentation behaviour.
This works because MT platforms that support glossary uploads treat the specified terms as translation constraints, not suggestions. If the glossary specifies that Datenschutzbeauftragter translates to "Data Protection Officer," the model will not output "data privacy commissioner" – regardless of what its training data implies.
Building a termbase for a new domain does not require translating every document first. The practical approach for a localization team:
Extract all compound nouns from a representative sample of source documents (this can be automated)
Identify which compounds have fixed, domain-specific target-language equivalents – particularly terms from DIN standards, EU regulations, or certified industry glossaries
Assign correct English translations and add them to the glossary before any MT processing begins
Review and update the termbase after each project cycle to capture newly coined compounds
The investment is front-loaded, but the payoff compounds across every subsequent project: fewer post-edit hours, fewer conformance findings, and consistent terminology across all documents regardless of when they were translated.
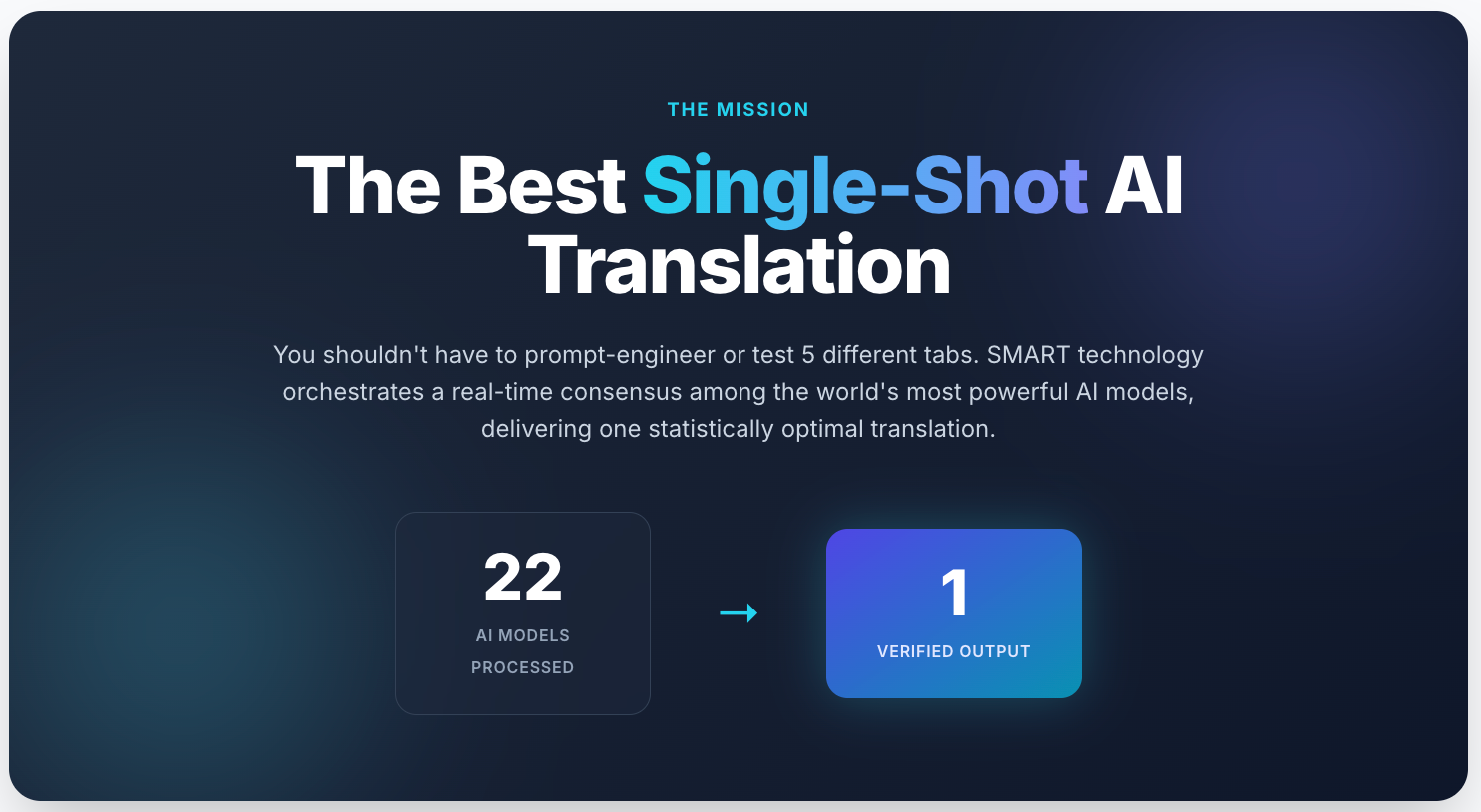
How MachineTranslation.com's SMART system addresses compound noun risk
MachineTranslation.com's English to German translation tool supports both the glossary-first approach and a separate mechanism for managing the residual uncertainty that glossaries cannot fully eliminate.
The SMART system runs the same source text through multiple AI models simultaneously and surfaces the outputs for comparison. For compound noun-heavy technical content, this is directly useful: different models segment and translate the same compound differently, and the comparison view makes those differences visible before the post-editor touches the document.
The practical workflow: upload the glossary, run MachineTranslation.com to compare multiple AI models at once and produce the most consistent compound noun handling for the specific domain, then send that output to post-editing. This narrows the post-editor's task from "catch all compound noun errors" to "verify and correct the residual variance that the glossary didn't cover."
For regulated-industry content where the compound noun density is high and the conformance stakes are real, this workflow materially reduces both the time and the expertise required at the post-editing stage.
FAQs
1. Why does AI struggle with German compound nouns more than other languages?
Most major AI translation systems are trained on corpora that skew heavily toward English, which builds complex concepts as multi-word phrases rather than single words. German's compounding rules produce single tokens that have no direct equivalent in the training data – particularly for rare, domain-specific, or newly coined compounds. The model must segment these tokens before translating them, and segmentation of unseen compounds is inherently uncertain.
2. Is there a compound noun length above which AI translation becomes unreliable?
Length alone is not the determining factor. A 30-character compound that appears frequently in training data will be translated more reliably than a 20-character compound from a narrow technical domain that appears rarely. The risk is better predicted by domain specificity and the compound's frequency in publicly available text than by character count alone.
3. Can I rely on machine translation for German technical documentation?
For most technical documentation, modern neural MT with glossary support produces output that is usable with targeted post-editing – particularly for documents with controlled vocabulary and established terminology. For certified documentation (medical devices, aviation, pharmaceuticals) where conformance requires exact terminology, professional post-editing by a domain expert is mandatory. MT accelerates the process; it does not replace the expert review.
4. How often should I update my German termbase?
Any time a new compound appears in source documents that is not already covered by the glossary, it should be evaluated for addition. In fast-moving industries (technology, pharmaceuticals, EU regulatory compliance), this means reviewing and updating the termbase at least quarterly. New compounds coined in EU legislation or technical standards should be added immediately when they appear, before the first document containing them is translated.
5. Does MachineTranslation.com support glossary upload for German translation projects?
Yes, MachineTranslation.com's German translation tool supports glossary uploads that constrain term selection during translation. The SMART system additionally allows comparison of multiple models outputs for the same source text, making it possible to identify which model handles a specific domain's compound nouns most consistently before committing to post-editing.