April 22, 2026
KI und deutsche Komposita: Warum maschinelle Übersetzung an langen Substantiven scheitert
Das Wort existiert tatsächlich: Rindfleischetikettierungsüberwachungsaufgabenübertragungsgesetz. 63 Zeichen, ein einziges Substantiv, beschlossen 1999 vom Landtag Mecklenburg-Vorpommern. Es regelte die Übertragung von Überwachungsaufgaben bei der Etikettierung von Rindfleisch. Das Gesetz wurde 2013 aufgehoben – das Wort lebt weiter, zumeist als Beispiel für die Fähigkeit der Deutschen, Sprache zu komprimieren.
Für KI-Übersetzungssysteme ist dieses Wort kein Kuriosum. Es ist ein Stresstest. Und das Ergebnis fällt selten befriedigend aus.
Dieser Artikel erklärt, warum deutsche Komposita maschinelle Übersetzungssysteme strukturell überfordern, welche Fehlertypen daraus entstehen, und was Unternehmen tun können, die täglich technische Texte mit langen Komposita ins Englische (oder aus dem Englischen ins Deutsche) übersetzen müssen.
Inhaltsverzeichnis
Was ist ein Kompositum und warum ist es für KI so schwer?
Die drei häufigsten Fehlertypen bei der maschinellen Übersetzung von Komposita
Warum Fachtexte besonders gefährdet sind
Wie Komposita in der Praxis Übersetzungsprojekte verzögern
Was KI-Übersetzer besser können als ihr Ruf und wo die Grenze liegt
Fazit: Das Kompositum-Problem ist lösbar, aber nicht ignorierbar
Häufig gestellte Fragen zur maschinellen Übersetzung deutscher Komposita
Was ist ein Kompositum und warum ist es für KI so schwer?
Ein deutsches Kompositum ist ein Wort, das aus zwei oder mehr selbständigen Wörtern zusammengesetzt wird – ohne Leerzeichen, ohne Bindestrich, ohne Grenze zwischen den Bedeutungsebenen. Die Sprache erlaubt dabei theoretisch unbegrenzte Länge. Ein neues technisches Konzept braucht kein Lehnwort: Das Deutsche bildet einfach ein neues Kompositum.
Für ein KI-Übersetzungssystem entsteht daraus ein fundamentales Problem: Das Modell muss entscheiden, wie ein Wort zu segmentieren ist, bevor es übersetzt werden kann. Sicherheitsventil Druckabfall kann als "safety valve pressure drop", "security valve pressure decrease" oder als mehrere andere Varianten interpretiert werden – je nachdem, wie das Modell das Wort zerlegt und welche Bedeutung es den Segmenten zuweist.
Bei häufigen Komposita aus dem Training Datenbestand ist das kein Problem. Bei seltenen, fachspezifischen oder neu gebildeten Komposita (also genau jenen, die in technischen Dokumentationen am häufigsten vorkommen) bricht das System strukturell ein.
Die drei häufigsten Fehlertypen bei der maschinellen Übersetzung von Komposita
Falscher Segmentierung Schnitt
Das Modell zerlegt das Kompositum an der falschen Stelle. Kraftstoff Einspritzpumpe (fuel injection pump) wird korrekt übersetzt, das Wort ist hinreichend häufig im Training. Kraftstoffeinspritzpumpe Gehäuse (fuel injection pump housing) werden dagegen manchmal inkonsistent aufgeteilt: einmal "fuel injection pump housing", einmal "fuel injection pump casing". Beide Varianten sind semantisch verständlich, aber in einem technischen Dokument, das durchgehend konsistente Terminologie erfordert, ist diese Variation ein Qualitätsproblem.
In regulierten Branchen (Medizintechnik, Luftfahrt, Maschinenbau) gehört terminologische Konsistenz zur Konformitätsanforderung. Schwankende Terminologie im gleichen Dokument ist dann kein Stil Problem, sondern ein Zertifizierungsproblem.
Wörtliche Rückübersetzung aus Einzelkomponenten
Das Modell übersetzt die Teile, nicht das Ganze. Datenschutzbeauftragter ist im deutschen Recht der "Data Protection Officer" (DPO), ein klar definierter Begriff aus der DSGVO. Ein Modell, das Datenschutz und Beauftragter separat verarbeitet, kann "data protection officer", "data privacy commissioner" oder "data protection agent" ausgeben. Alle drei sind semantisch verständlich. Nur eine ist rechtlich korrekt.
Dasselbe gilt für Verwaltungskomponente der öffentlichen Hand, für Produktbezeichnungen und für normierte Fachbegriffe aus DIN-Normen oder EU-Richtlinien. Die Übersetzung klingt plausibel und ist falsch.
Nicht-Übersetzung oder Transliteration
Bei sehr langen oder seltenen Komposita kapitulieren manche Modelle schlicht: Sie lassen das deutsche Wort unübersetzt stehen oder geben eine phonetische Annäherung aus. In einem englischsprachigen Produkthandbuch, das aus einem deutschen technischen Dokument übersetzt wurde, tauchen dann deutsche Substantive auf – für den End Leser unverständlich, für Qualitätsprüfer ein sofortiges Warnsignal.
Warum Fachtexte besonders gefährdet sind
Die Alltagssprache enthält wenige überraschende Kompositionen. Tisch, Fenster, Straße – diese Wörter sind im Training Korpus jedes großen Sprachmodells tausendfach vertreten. Die Übersetzung ist stabil und zuverlässig.
Fachtexte funktionieren anders. In der Fertigungsindustrie entstehen Komposita für Bauteile, die erst seit wenigen Jahren existieren. In der Pharmaindustrie werden Wirkstoffkombinationen durch Komposita beschrieben, die in keiner öffentlichen Trainingsdatenbank auftauchen. Im Bereich der EU-Regulierung (besonders seit der DSGVO und dem AI Act) entstehen ständig neue Verwaltungs Komposita, die Rechtspflichten in einem einzigen Wort bündeln.
Die Folge ist vorhersehbar: Je spezifischer das Fachgebiet, desto wahrscheinlicher ist ein Komposita-Fehler. Und Fachtexte sind genau jene Texte, bei denen ein Fehler die teuersten Konsequenzen hat.
Wie Komposita in der Praxis Übersetzungsprojekte verzögern
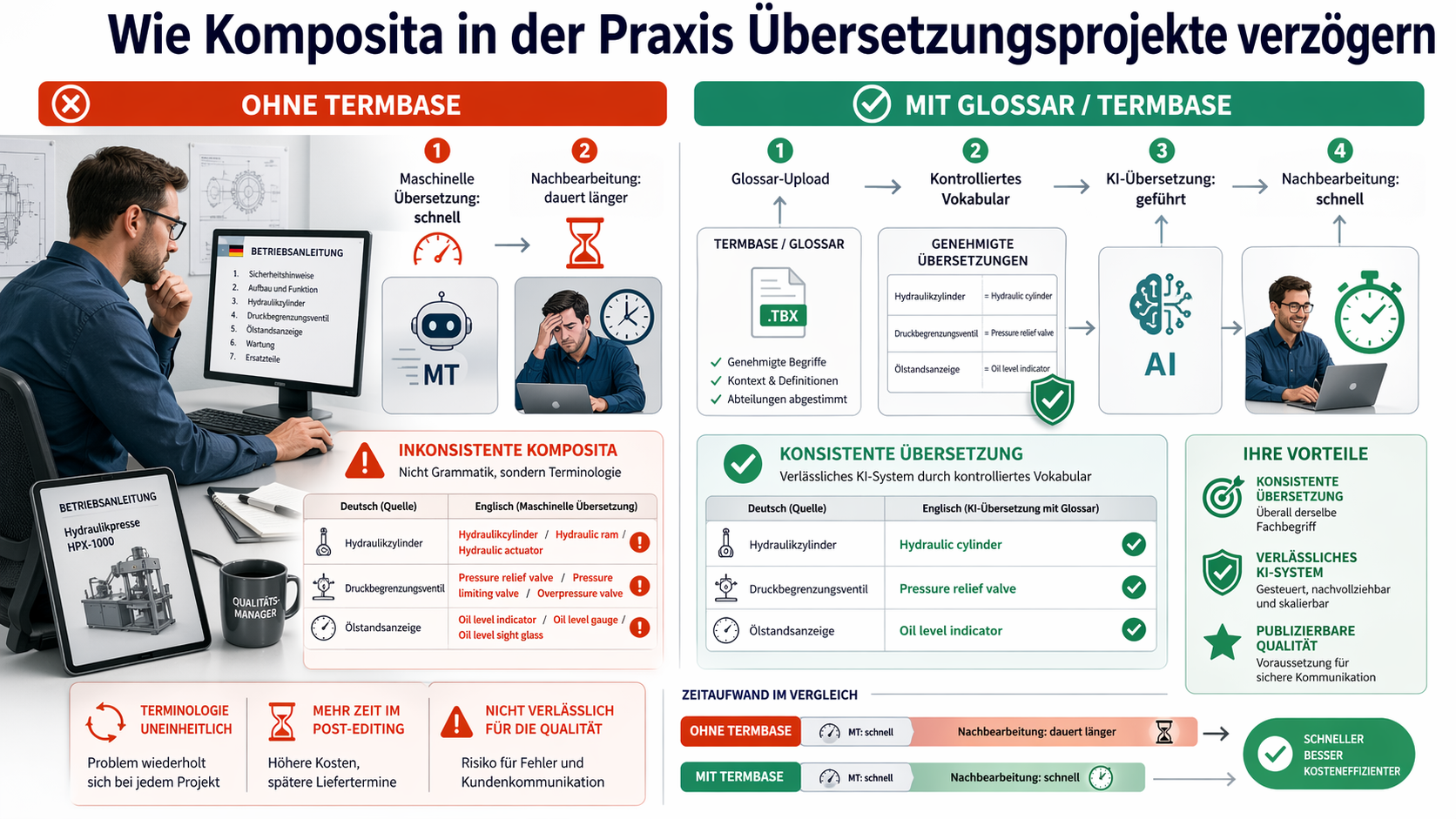
Ein Qualitätsmanager in einem deutschen Maschinenbauunternehmen, der technische Handbücher ins Englische übersetzen lässt, kennt das Problem aus der Praxis. Die erste maschinelle Übersetzung ist schnell verfügbar. Die Nachbearbeitung durch den Post-Editor dauert deutlich länger – nicht wegen grammatischer Fehler, sondern wegen terminologischer Inkonsistenz bei Komposita, die das System unterschiedlich übersetzt hat, obwohl sie dasselbe Bauteil bezeichnen.
Ohne eine gepflegte Termbase, die dem Übersetzungssystem vor der Übersetzung mitgeteilt wird, wiederholt sich dieses Problem bei jedem Projekt. Mit einem kontrollierten Vokabular genehmigter Übersetzungen für fachspezifische Komposita (einem sogenannten Glossar) wird das KI-System zum verlässlichen Werkzeug statt zur Fehlerquelle.
Wer mit einem KI-gestützten Übersetzungstool für Englisch-Deutsch-Übersetzungen arbeitet, das Glossar-Uploads unterstützt, kann diese Termine vorab festlegen. Das System übernimmt sie und verwendet sie konsistent im gesamten Dokument. Für Unternehmen, die regelmäßig technische Texte übersetzen, ist das keine Komfortfunktion – es ist eine Voraussetzung für publizierbare Qualität.
Was KI-Übersetzer besser können als ihr Ruf und wo die Grenze liegt
Die Kritik an maschineller Übersetzung bei Komposita ist berechtigt, aber sie ist einseitig. Für häufige Domänen (kaufmännische Korrespondenz, allgemeine technische Dokumentation mit kontrolliertem Vokabular, E-Commerce-Produktbeschreibungen) liefern moderne neuronale Systeme bei Deutsch-Englisch eine Qualität, die mit gezieltem Post-Editing direkt verwendbar ist.
Die Grenze liegt beim seltenen Fach Komposita, bei rechtsverbindlichen Dokumenten und bei Texten, in denen terminologische Konsistenz zur Konformitätsanforderung gehört. Hier ist KI ein erster Entwurf, kein Endprodukt.
Das SMART-System von MachineTranslation.com vergleicht die Ausgabe von bis zu 22 KI-Modellen gleichzeitig und identifiziert, welches Modell für den jeweiligen Text die konsistentes Terminologie liefert. Für technische Texte mit vielen Komposita bedeutet das: statt blind auf ein einziges Modell zu vertrauen, kann die beste Ausgabe für den spezifischen Text identifiziert werden – bevor der Post-Editing-Prozess beginnt.
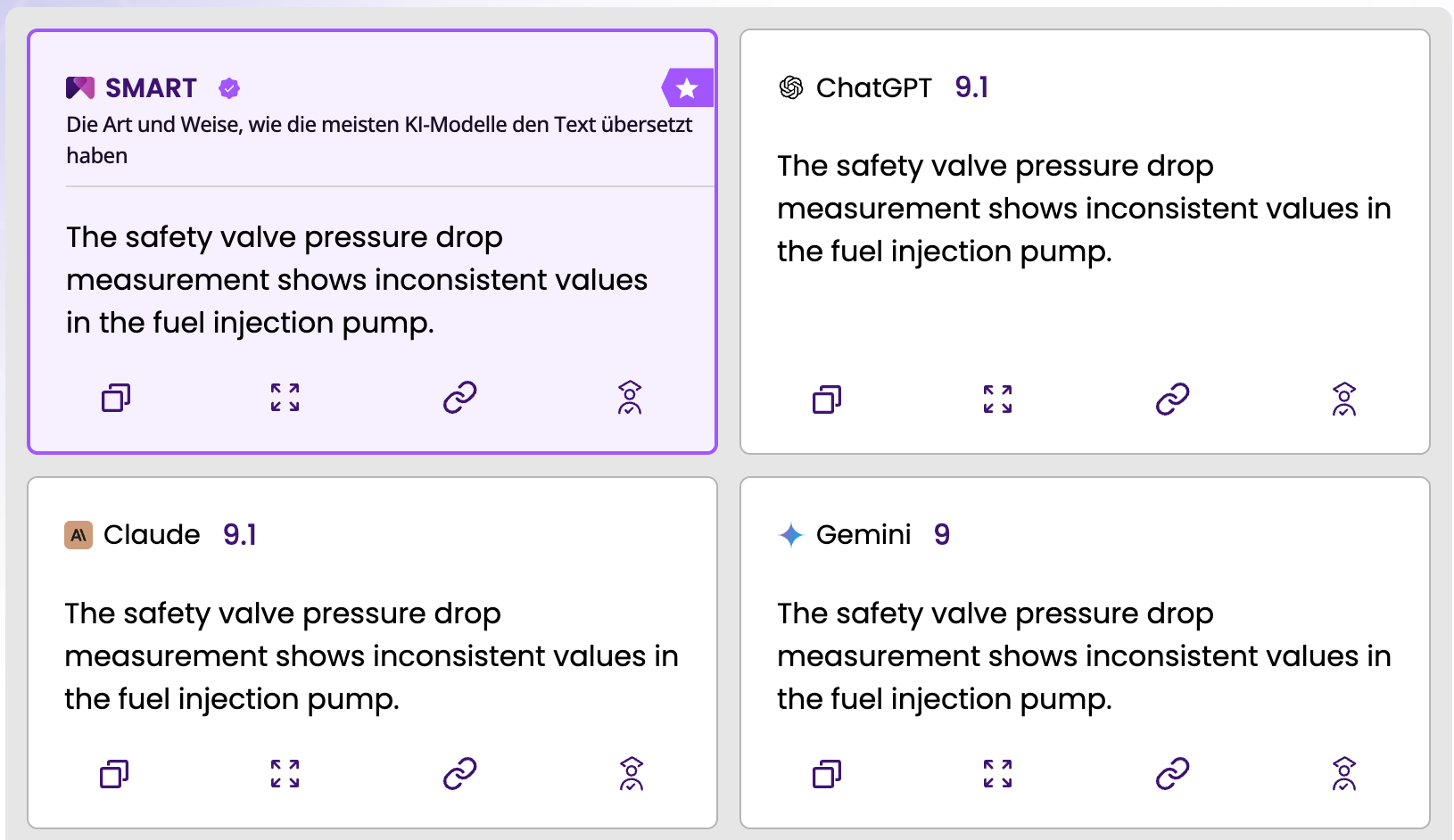
Die Kombination aus Glossar-Upload für Terminologiekontrolle und SMART-Modellvergleich für Qualitätsauswahl verändert das Risikoprofil von technischen Übersetzungen grundlegend. Kein System eliminiert das Kompositum-Problem vollständig. Aber diese zwei Mechanismen reduzieren die Fehlerquote auf ein Niveau, das mit vertretbarem Post-Editing-Aufwand korrigierbar ist.
Fazit: Das Kompositum-Problem ist lösbar, aber nicht ignorierbar
Deutsch ist eine der am häufigsten übersetzten Sprachen im technischen und rechtlichen Unternehmensumfeld. Das Kompositum-Problem verschwindet nicht, es ist strukturell in der Sprache verankert. Aber es ist beherrschbar: mit Glossaren, mit Modell Verglichen, mit gezieltem Post-Editing und mit einem klaren Verständnis dafür, welche Dokumente welche Qualitätsstufe erfordern.
Unternehmen, die diese Entscheidungen bewusst treffen, verschwenden weniger Zeit auf Korrekturen und investieren stattdessen in Texte, die beim ersten Mal korrekt sind.
Häufig gestellte Fragen zur maschinellen Übersetzung deutscher Komposita
1. Warum macht KI bei deutschen Komposita häufiger Fehler als bei englischen Texten?
Das Englische bildet zusammengesetzte Konzepte meist als Mehrwortphrasen, nicht als einzelne Wörter. KI-Modelle, die auf englisch-dominierten Korpora trainiert wurden, sind strukturell besser auf Phrasen Übersetzung ausgerichtet als auf die Zerlegung und Reinterpretation langer Einzelwörter. Deutsche Komposita erfordern einen zusätzlichen Segmentierung Schritt, bei dem seltene oder neue Wörter systematisch fehleranfällig sind.
2. Helfen Glossare dabei, Kompositum-Übersetzungsfehler zu vermeiden?
Ja – für bekannte, dokumentierte Komposita ist ein gepflegtes Glossar der effektivste Schutz. Wenn das Übersetzungssystem vor dem Start weiß, dass Sicherheitsventil Druckabfall als "safety valve pressure drop" zu übersetzen ist, wird dieser Term konsistent und korrekt im gesamten Dokument verwendet. Glossare helfen nicht bei unbekannten, neu gebildeten Komposita – dafür bleibt der menschliche Post-Editor unverzichtbar.
3. Ab welcher Zeichenanzahl werden Komposita für KI-Systeme problematisch?
Es gibt keine universelle Zeichengrenze. Die Fehlerwahrscheinlichkeit steigt mit der Seltenheit des Kompositums, nicht allein mit der Länge. Ein 25-Zeichen-Kompositum aus einem spezialisierten Rechtstext ist fehleranfälliger als ein 35-Zeichen-Kompositum, das in hunderttausenden technischen Dokumenten vorkommt. Länge und Seltenheit zusammen erhöhen das Risiko am stärksten.
4. Sollte ich für technische Dokumente auf die maschinelle Übersetzung verzichten?
Nicht pauschal. Für Fachtexte mit kontrolliertem Vokabular und einem gepflegten Glossar liefert moderne maschinelle Übersetzung eine belastbare Basis, die mit gezieltem Post-Editing deutlich effizienter ist als eine vollständige Neuübersetzung durch einen menschlichen Übersetzer. Die Entscheidung hängt vom Risiko des Dokuments ab: Bei rechtsverbindlichen Texten, Zertifizierungsunterlagen und Sicherheitsdokumentationen ist professionelles Post-Editing obligatorisch, nicht optional.
5. Wie unterscheidet sich MachineTranslation.com bei der Übersetzung von Fach Komposita von anderen Tools?
MachineTranslation.com unterstützt den Glossar-Upload vor der Übersetzung und vergleicht die Ausgabe mehrerer KI-Modelle gleichzeitig über das SMART-System. Für Texte mit vielen Fach Komposita erlaubt das, jenes Modell zu identifizieren, das die konsistentes Terminologie liefert. Die Englisch-Deutsch-Übersetzungsfunktion ist auf die Anforderungen professioneller Fachtextübersetzung ausgelegt, einschließlich Glossar-gestützter Terminologiekontrolle.