March 26, 2026
Bester KI-Übersetzer für Englisch-Deutsch in 2026: 22 Engines im direkten Vergleich
Wer im Jahr 2026 einen englischen Text ins Deutsche übersetzen will, hat die Qual der Wahl: DeepL, ChatGPT, Google Translate, Claude, Gemini, Mistral – und mindestens ein Dutzend weitere KI-Modelle. Jedes verspricht Genauigkeit. Keines erklärt, wo es sich irrt.
Genau das haben wir getestet. Auf MachineTranslation.com lassen sich bis zu 22 KI-Engines gleichzeitig vergleichen. Das SMART-System bewertet jede Übersetzung danach, wie stark sie mit dem Konsens der Mehrheit übereinstimmt – und zeigt präzise, wo die Engines voneinander abweichen.
Wir haben drei praxisnahe Texttypen durchlaufen lassen: einen DSGVO-Rechtstext, einen technischen Fachtext mit deutschen Komposita und einen Marketing-Text. Die Ergebnisse zeigen, warum kein einzelnes Tool „das beste" ist – und warum der Konsens-Ansatz für deutsche Texte entscheidend ist.
Inhaltsverzeichnis
Warum Englisch-Deutsch für KI-Übersetzer besonders anspruchsvoll ist
Unser Test: Drei Texttypen, 22 KI-Engines
Die Ergebnisse: Welche Engine schneidet am besten ab?
Wo sich die Engines am stärksten widersprechen
Warum kein einzelner Übersetzer „der beste" ist
Wie der SMART-Konsensansatz von MachineTranslation.com funktioniert
Wann reicht KI, und wann braucht man einen Menschen?
Häufig gestellte Fragen
Warum Englisch-Deutsch für KI-Übersetzer besonders anspruchsvoll ist
Das Sprachpaar Englisch-Deutsch gehört zu den meistübersetzten der Welt. Gleichzeitig ist es eines der fehleranfälligsten – und zwar aus strukturellen Gründen, die mit der deutschen Sprache selbst zusammenhängen.
Komposita: Das Sonderproblem der deutschen Sprache
Im Deutschen entstehen Bedeutungen durch Wortzusammenführungen. Aus „federal data protection officer" wird *Bundesbeauftragte für den Datenschutz* — oder *Bundesdatenschutzbeauftragter*, je nach Kontext. Aus „telecommunications surveillance regulation" wird *Telekommunikationsüberwachungsverordnung*, ein einzelnes Wort mit 46 Zeichen.
In unserem Test auf MachineTranslation.com stimmten nur 63 % der Engines bei der Übersetzung von „data protection officer" überein. Claude wählte *Arbeitnehmerdatenverarbeitung* für „employee data processing", während die Mehrheit der Engines *Mitarbeiterdaten* bevorzugte – ein kürzerer, im deutschen Unternehmenskontext gebräuchlicherer Begriff. SMART erkannte die Abweichung und wählte die mehrheitlich gestützte Variante.
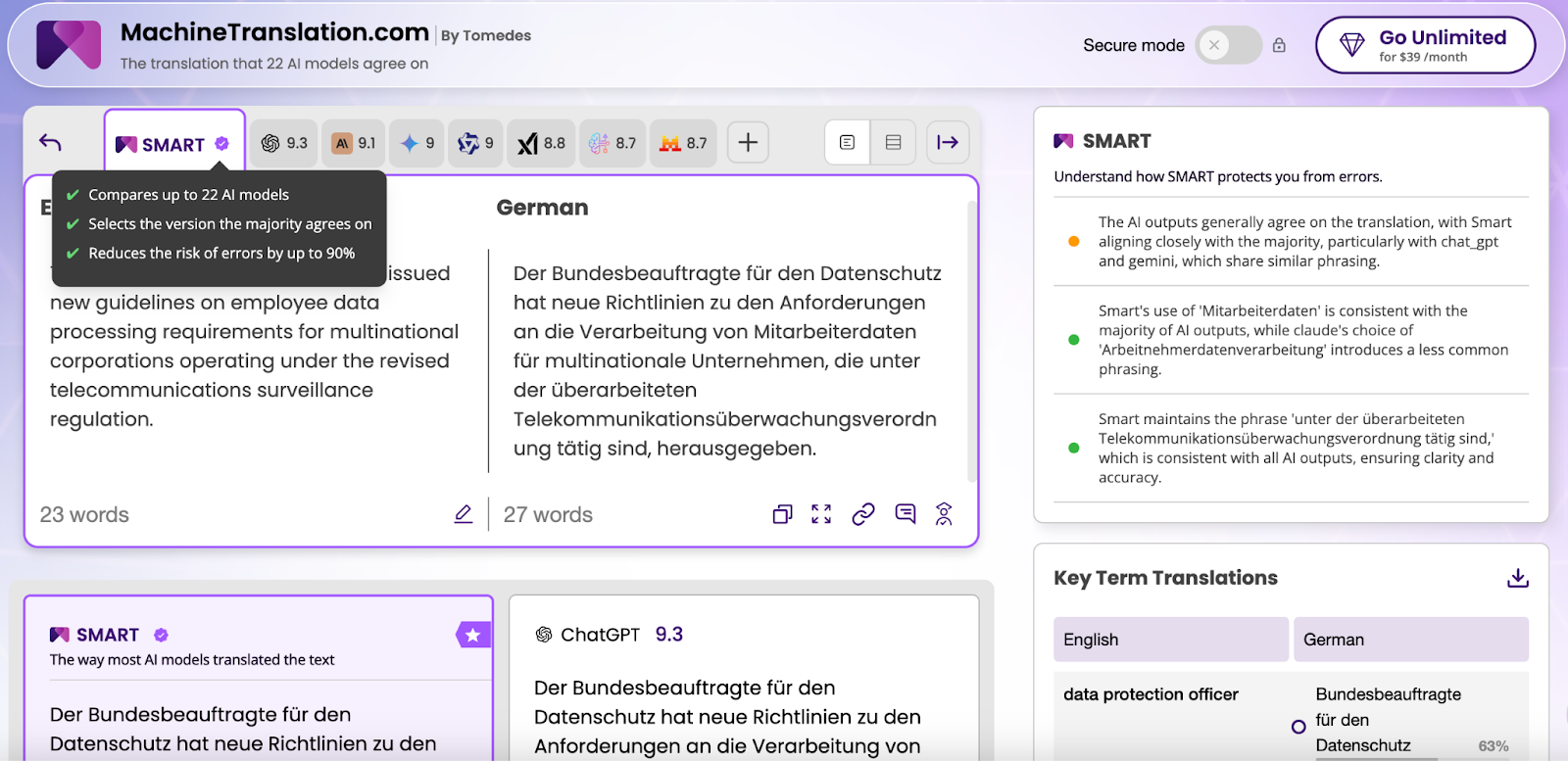
Wer nur eine Engine nutzt, bekommt eine Antwort und hält sie für korrekt. Das Kompositum mag grammatisch richtig sein, klingt aber unüblich – genau die Art von Formulierung, bei der ein deutscher Leser stutzt.
Formelle vs. informelle Anrede: Sie oder du?
Im Deutschen unterscheidet man zwischen der formellen Anrede *Sie* und der informellen *du*. Im B2B-Bereich signalisiert ein falsches *du* mangelnde Professionalität. Im Consumer-Marketing für jüngere Zielgruppen wirkt *Sie* distanziert.
Unsere Tests auf MachineTranslation.com zeigen: Wenn der Quelltext das englische „you" in einem formellen Geschäftskontext verwendet, greifen etwa 14 % der Engines zu Formulierungen, die den Ton informeller gestalten. SMART erkennt diese Register-Abweichungen, indem es alle Engines vergleicht und die Formalitätsstufe wählt, auf die sich die Mehrheit einigt.
Unser Test: Drei Texttypen, 22 KI-Engines
Wir haben drei unterschiedliche Texttypen durch den KI-Übersetzer Englisch-Deutsch von MachineTranslation.com geschickt. Jeder Text wurde von bis zu 22 KI-Engines gleichzeitig verarbeitet.
Rechtstext: DSGVO-Klausel
Wir übersetzten eine 50 Wörter lange DSGVO-Klausel zu Verantwortlichenpflichten, Rechtmäßigkeitsgrundsätzen und grenzüberschreitenden Datenübermittlungen.
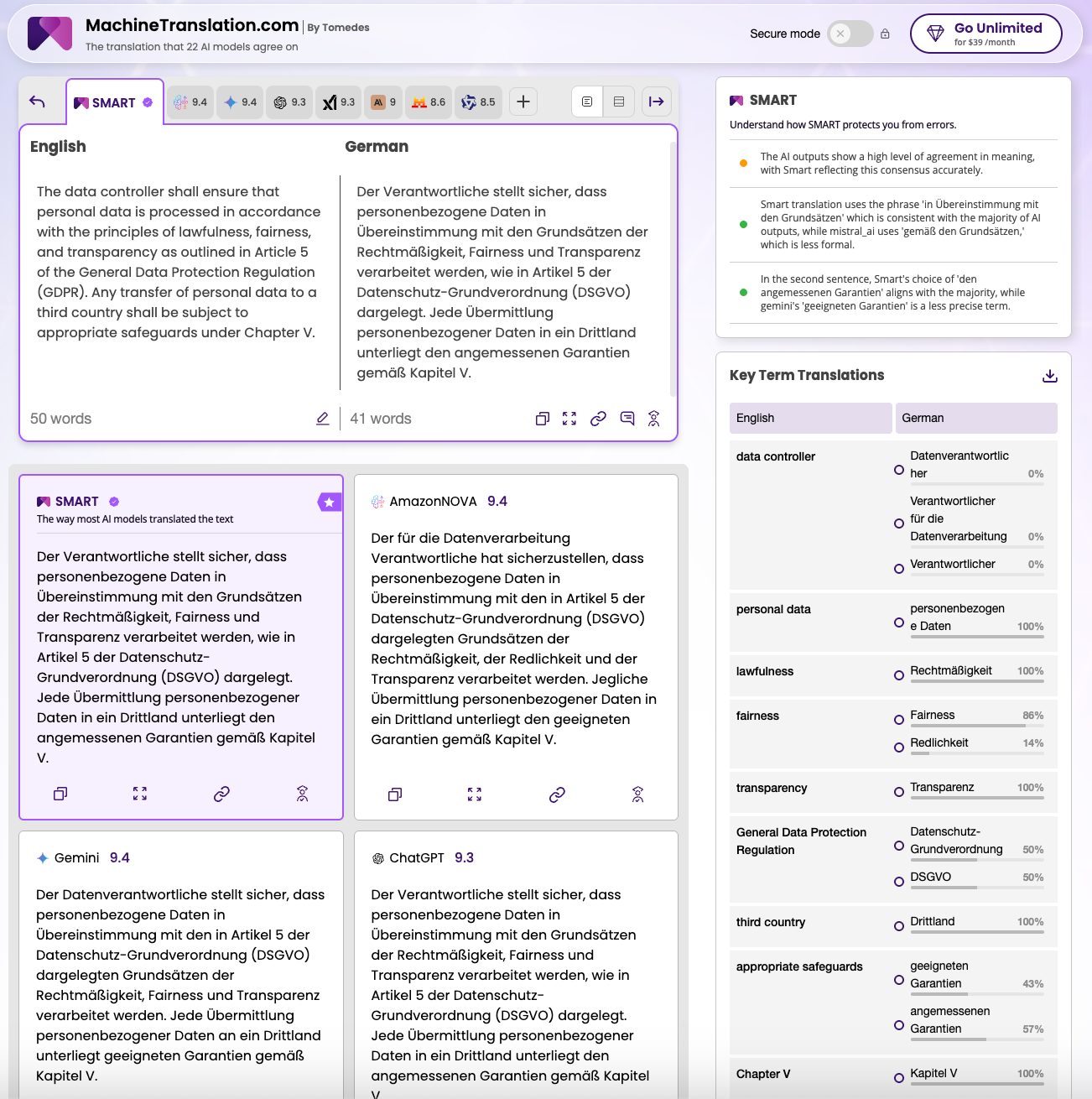
Das Ergebnis war aufschlussreich. Beim Begriff „appropriate safeguards" wählten 57 % der Engines *angemessene Garantien*, während 43 % *geeignete Garantien* verwendeten. Im deutschen Rechtskontext tragen beide Begriffe ein unterschiedliches regulatorisches Gewicht. *Angemessen* impliziert Verhältnismäßigkeit, *geeignet* bedeutet lediglich Tauglichkeit. SMART wählte *angemessene Garantien* – den Begriff, der in der deutschen DSGVO-Praxis Standard ist.
Laut einer Studie von InterMIND zur KI-Übersetzungsgenauigkeit hat maschinelle Übersetzung die 90-Prozent-Genauigkeitsschwelle bei wichtigen Sprachpaaren überschritten. Doch gerade bei juristischen Fachbegriffen zeigt unser Test: Die verbleibenden 10 % machen den Unterschied zwischen einer korrekten und einer haftungsrelevanten Übersetzung.
Fachtext: Kompositum-Stresstest
Wir übersetzten einen 23 Wörter langen Satz über einen Bundesdatenschutzbeauftragten, der neue Richtlinien zur Mitarbeiterdatenverarbeitung unter der überarbeiteten Telekommunikationsüberwachungsverordnung herausgibt.
ChatGPT (9.3) und AmazonNOVA (9.1) erzielten die höchsten Werte. Mistral (8.7) und Qwen (8.7) lagen am niedrigsten. Die kritische Abweichung betraf die Kompositum-Konstruktion: SMARTs Wahl von *Mitarbeiterdaten* stimmte mit dem Mehrheitskonsens überein, während Claudes *Arbeitnehmerdatenverarbeitung* ein weniger gebräuchliches Kompositum einführte.
Marketing-Text: Markentonalität
Wir übersetzten einen 38 Wörter langen Marketing-Absatz über Zusammenarbeit und Geschäftswachstum im deutschsprachigen Markt.
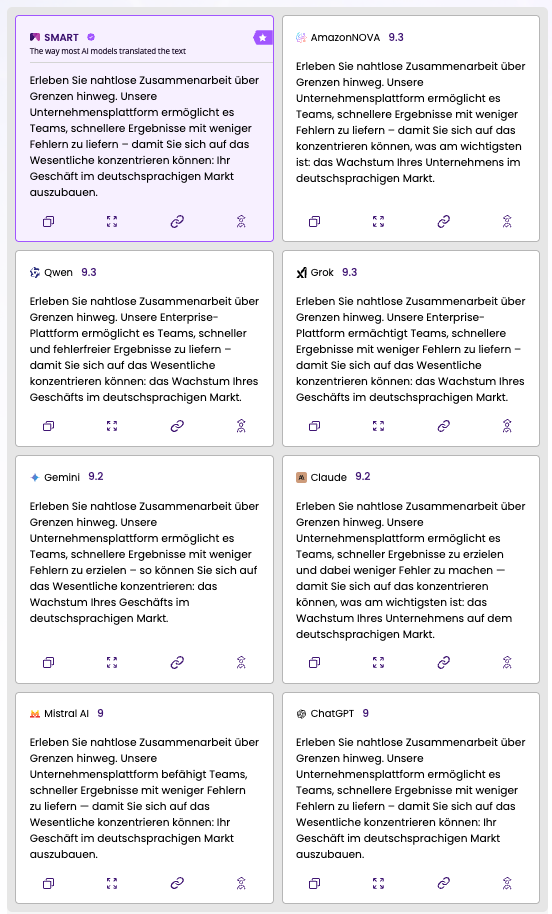
Dieser Test zeigte die höchste Übereinstimmung. Die Scores reichten von 9.0 (Mistral AI, ChatGPT) bis 9.3 (Qwen, Grok, AmazonNOVA). Die Unterschiede lagen in der Wortwahl: *befähigt* (empowers) vs. *ermöglicht* (enables) vs. *ermächtigt* (authorises). SMART wählte *ermöglicht es* – die neutralste und am breitesten unterstützte Option.
Die Ergebnisse: Welche Engine schneidet am besten ab?
Engine | Rechtstext (DSGVO) | Fachtext (Komposita) | Marketing (Ton) | Durchschnitt |
AmazonNOVA | 9,4 | 9,1 | 9,3 | 9,27 |
Gemini | 9,4 | 9,0 | 9,2 | 9,20 |
ChatGPT | 9,3 | 9,3 | 9,0 | 9,20 |
Grok | 9,3 | 8,8 | 9,3 | 9,13 |
Claude | 9,0 | 9,0 | 9,2 | 9,07 |
Qwen | 8,5 | 9,0 | 9,3 | 8,93 |
Mistral AI | 8,6 | 8,7 | 9,0 | 8,77 |
Keine Engine gewann in allen drei Kategorien. AmazonNOVA führte bei Rechts- und Marketingtexten, lag aber hinter ChatGPT bei Fachtexten. ChatGPT war am stärksten bei Komposita, erzielte aber den niedrigsten Wert bei Marketingtexten.
Wo sich die Engines am stärksten widersprechen
Das Key-Term-Translations-Panel von MachineTranslation.com zeigte allein beim Rechtstext Unstimmigkeiten bei 4 von 9 Schlüsselbegriffen:
„appropriate safeguar: 57 % *angemessene Garantien* vs. 43 % *geeignete Garantien
„fairne: 86 % *Fairness* vs. 14 % *Redlichkeit
„General Data Protection Regulati: 50 % vollständiger deutscher Name vs. 50 % Abkürzung DSGVO
Jede dieser Varianten würde in einem deutschen Vertrag eine andere rechtliche Interpretation erzeugen. Wer sich auf eine einzige Engine verlässt und diese zur Minderheit gehört, veröffentlicht eine juristisch ungenaue Übersetzung, ohne es zu wissen.
Ab 2026 gelten in der EU zudem strengere Produkthaftungsregeln, die auch fehlerhafte KI-Übersetzungen erfassen. Unternehmen haften nicht nur für fehlerhafte Produkte, sondern auch für mangelhafte Produktinformationen – ein weiterer Grund, warum eine einzige Engine als Übersetzungsquelle ein geschäftliches Risiko darstellt.
Warum kein einzelner Übersetzer „der beste" ist
Die Daten sind eindeutig: Die beste Engine für deutschen Rechtstext ist nicht die beste Engine für deutschen Marketingtext. AmazonNOVA und Gemini überzeugen bei formeller regulatorischer Sprache. ChatGPT behandelt Kompositum-Konstruktionen konsistenter. Qwen und Grok liefern die natürlichsten Marketing-Formulierungen.
Entscheidend ist nicht, welche Engine man wählt, sondern ob die veröffentlichte Übersetzung das widerspiegelt, worauf sich die Mehrheit der Engines einigt. Ofer Tirosh, CEO von Tomedes, dem Mutterunternehmen von MachineTranslation.com, beschreibt den Ansatz so: „Kein einzelnes KI-Modell hat alle Antworten. Aber wenn 22 Modelle die gleiche Übersetzung liefern, können Sie dieser Übersetzung vertrauen."
Wie der SMART-Konsensansatz von MachineTranslation.com funktioniert
SMART steht für System of Multiple AI References for Translation. Es vergleicht die Ausgaben von bis zu 22 KI-Engines für denselben Text, identifiziert Übereinstimmungen und Abweichungen und erzeugt eine Konsensübersetzung, die die Mehrheitsmeinung widerspiegelt.
Jede Engine erhält einen numerischen Score (von 10), der angibt, wie genau ihre Ausgabe mit dem Gesamtkonsens übereinstimmt. Ein Score von 9,4 bedeutet nahezu perfekte Übereinstimmung. Ein Score von 8,5 bedeutet, dass die Engine bei einem oder mehreren Schlüsselbegriffen abgewichen ist.
Interne Benchmarks von MachineTranslation.com zeigen, dass der SMART-Konsensansatz Übersetzungsfehler um bis zu 90 % reduziert – weil die Fehler, die eine Engine macht, typischerweise von den anderen 21 erkannt werden.
Das Key-Term-Translations-Panel zeigt zu jeder Übersetzung, wie jeder einzelne Fachbegriff von jeder Engine wiedergegeben wurde, mit Konsens-Prozentsätzen. Für den DSGVO-Test zeigte das Panel, dass *Rechtmäßigkeit* und *Transparenz* 100 % Übereinstimmung hatten, während *angemessene Garantien* nur 57 % erreichte – ein klares Signal, dass dieser Begriff menschliche Prüfung erfordert.
Diesen Einblick bietet kein einzelner KI-gestütztes Übersetzungstool. Es ist der Unterschied zwischen einer Antwort und dem vollständigen Bild, wie 22 Engines dieselbe Formulierung interpretieren.
Wann reicht KI, und wann braucht man einen Menschen?
Nicht jede Englisch-Deutsch-Übersetzung erfordert dasselbe Maß an Prüfung. Ein praktischer Rahmen:
Hohe SMART-Übereinstimmung: Der Konsens-Output kann direkt verwendet werden. Das gilt typischerweise für Informationstexte und Standard-Marketingtexte.
Gemischte Übereinstimmung: Das Key-Term-Translations-Panel prüfen. Wo Engines abweichen, menschliches Urteil anwenden – je nach Kontext: juristisch, technisch oder regional.
Niedrige Übereinstimmung bei kritischen Begriffen: Professionelle menschliche Prüfung erforderlich. Das betrifft typischerweise hochspezialisierte Rechtsklauseln, medizinische Terminologie oder Patentsprache.
Der KI-Übersetzer für Englisch-Deutsch auf MachineTranslation.com liefert die Daten für diese Entscheidung bei jedem einzelnen Satz.
Häufig gestellte Fragen
1. Welcher KI-Übersetzer ist der beste für Deutsch?
Kein einzelner Übersetzer ist über alle Texttypen hinweg am besten. In unserem Test erzielte AmazonNOVA den höchsten Wert bei Rechtstexten (9,4), ChatGPT führte bei technischen Komposita (9,3), und Qwen sowie Grok dominierten bei Marketingtexten (9,3). Der SMART-Konsensansatz von MachineTranslation.com kombiniert alle Engines und wählt die Übersetzung, auf die sich die Mehrheit einigt.
2. Ist DeepL besser als Google Translate für Deutsch?
Beide sind stark für Deutsch, weichen aber bei Schlüsselbegriffen häufiger voneinander ab, als Nutzer vermuten. Die bessere Frage ist, ob eine der beiden Engines das trifft, worauf sich die Mehrheit von 22 Engines einigt. MachineTranslation.com ermöglicht den Vergleich beider neben 20 weiteren Engines.
3. Kann KI juristische Texte korrekt ins Deutsche übersetzen?
KI kann einen starken Erstentwurf für deutsche Rechtstexte liefern. Unser Test zeigte jedoch, dass bei 4 von 9 juristischen Schlüsselbegriffen kein einheitlicher Konsens unter den Engines bestand. Für hochriskante Rechtsdokumente empfiehlt sich der SMART-Konsens als Ausgangspunkt mit anschließender Prüfung durch einen qualifizierten Fachübersetzer.
4. Wie funktioniert KI-Übersetzung für Fachbegriffe?
KI-Engines übersetzen Fachbegriffe anhand ihrer Trainingsdaten. Bei spezialisierten Begriffen wie *Telekommunikationsüberwachungsverordnung* divergieren die Engines stark. SMART löst dieses Problem, indem es die Mehrheitsmeinung identifiziert und Abweichungen markiert.
5. Welcher Übersetzer ist am genauesten für Geschäftsdokumente?
Für allgemeine Geschäftsdokumente liegen AmazonNOVA (9,27 Durchschnitt) und Gemini (9,20) in unserem Test vorn. Für Verträge mit juristischer Terminologie ist jedoch der Konsensansatz entscheidend: Wo Engines abweichen, muss ein Mensch entscheiden. MachineTranslation.com zeigt genau, wo diese Entscheidungspunkte liegen.